Introduction
Business intelligence platforms are traditionally for strategic decisions, but requirements are more for operational analytics nowadays.For example, bed planning in a hospital is mostly based on surgery planning. A dashboard with fresh updates highlighting the number of external extra nurses required is valuable.
These operational business intelligence platforms have one or more of the following in common :
More frequent data refresh than traditional nightly batch
Expose data to a wider array of tool than traditional corporate business intelligence tool ( like Tableau, PowerBi,...)
Need to take action based on analysis ( if data from the sensor show something critical, do something )
Scale horizontally, need the ability to add compute/storage resources during the timeline so handle additional workload.
These requirements drive different types of architecture; the following show the different key factors strongly influencing architecture for an operational analytics platform; there are, of course, way more factors than these. Also, lambda architecture can be added to a lakehouse approach to satisfy both operational analytics and operational scenarios. Lambda architecture will be for another post.
These are only key points; hire a data architect before proceeding with an architecture.
Let’s recap how Business intelligence architecture evolved through time.
Early adopter, storage and computing mixed.
Business intelligence traditionally relies on relational databases to store, transform, and present data. Relational databases have evolved and can now handle structured and unstructured data very well ( just look at Postgresql's latest version, json capabilities are impressive ). Also, they deal very well with binary data and files. Their engines are very efficients in computing row-oriented datasets. The term relational database should not be confused with SQL engine. SQL is a language. Relational databases ( Microsoft SQL Server,Postgresql,Oracle,Mysql) include both the SQL engine and the storage. They are optimised for OLTP workload and not for analytical workload yet ( I separate them from MPP engines, which are indeed good at OLAP). Also ( for now, the adoption of Apache arrow is changing that), every time you need to export a large analytical dataset, RDMS use an inefficient ODBC/JDBC interface that serializes and deserialises row-oriented datasets.
The early stage of a new platform
Two decades ago came the big data “revolution”. It was the T-14 armada tank of the data world. Completely Inefficient for actual corporations. Why? Solving a problem that didn’t exist in most companies. Yes, it’s amazing to deal with any supercollider dataset, but otherwise, it’s an expensive overkill.
The idea was to separate the compute and the storage of the datastore, the compute started it’s journey with map-reduce and the storage on an early stage of the distributed filesystem with Hadoop Distributed file system (HDFS). Sacrificing latency for raw bandwidth/throughput, redundancy, and scalability. The concept was interesting. Also, anchor modelling approach ( ex Datavault ) adoption improved. This new modelling emphasises the modular approach and use of business keys instead of surrogate keys. This avoids large lookups and overuse of joins that only relational databases were capable of at the time.
The young adult stage
Then, some common sense arose, and instead of using an overly complicated computing engine, the like of Spark/Databrick appeared. Let’s use cheap, abundant RAM on modern hardware instead of an integrated complex engine.
The concept is simple: waste CPU and RAM for fast and simple computation. Next was the wide adoption and integration of Pandas framework. It allows impressive code simplification to reduce labour costs and ease evolutive maintenance. SQL is very, very bad for metadata-oriented transformation. Let’s say you have a dataset coming from CDC; for each row, you have the previous and new values. You need to compare each group's first and second rows for every non-PK column. It will take a whopping amount of code to do so ( >5000 if you don’t want to crash your tempdb) because without tricking it, SQL forces you to name the columns. With Pandas, it takes 9 lines of code; the maintenance cost will align with the amount of code.
In Switzerland, a day of consultant labour is above 1000 chf/euro/usd and 32 Go of ram is 100 chf/usd/chf. It became a no-brainer for small and medium-sized datasets ( any dataset with the biggest table under 1 TB of data ).
Storage started to mature with online object storage of AWS and their S3 protocol,Azure and ADLS v2. Binary immutable datafile (parquet ) became a standard.
Tools to generate modular modelling gain in popularity ( Wherescape,BIML, etc.) and improve computing usage without long repetitive code.
Finally, a mature stage?
Data Lake keeps maturing. Databrick makes their Delta Lake storage format open source. This format adds a transaction file to “update “ data in the data lake. S3 fixed their problem about concurrent write issues. So now we have a situation where we can scale storage and compute and manage a "real-time" data stream within a new concept named Lakehouse. Lakehouse is simply a data lake that can update the data instead of just append it.
Distributed compute mature and efficient memory management comes into play, hence the introduction of Pandas 2.x + Apache Arrow, but yet to be battle-tested. Single-node solutions for computing, like Polars and Duckdb, simplify architecture for middle-size datasets and offer very cost-effective options. However, they are still very new to the landscape.
What does it look like ? A computing engine pulls/transform data from either a batch or stream of data into an object storage. Tables are stored in a Delta lake format ( parquet files+ transactions files + metadata files). Instead of a monolith platform like a relational database. We have a three-tier approach :
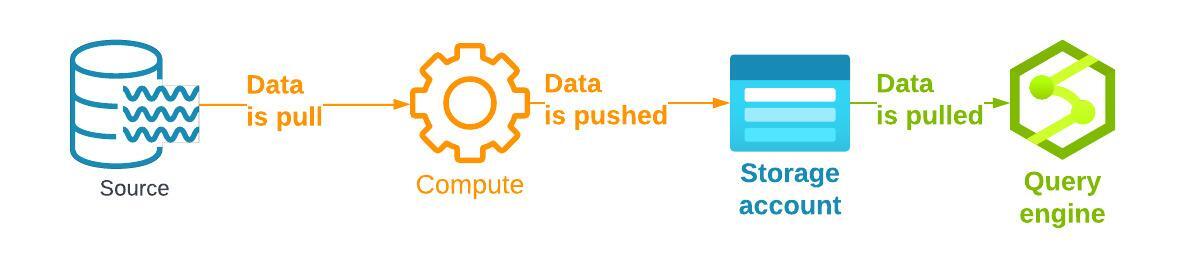
How to choose if a Lakehouse approach is right for you?
First and foremost, assess the business needs and weigh each requirement's actual value. Second, do you have the skill in your pool to modernise your data platform? If getting it (training, consulting, hiring) is higher than the expected return on investment. Don’t do it.
Company culture is also very important; all companies advertise their ability to change, but only a few are good at it. Modern data platforms involve a lot of changes in how we think about the data, especially in how we model them. Modelling for flexibility is very different. It requires a lot of training. If your data team is not ready for it, don’t do it.
Besides a decision tree as a guideline for operational analytic architecture, blue-filling is a business requirement you would like to fulfil. Purple is a skill required. Green is a decision.
Conclusion
The data landscape is a passionate field to work in these days with a lot of possibilities; as new technologies arise, we need to adapt how we model, how we code, and how we design our platform. So it's a never-ending cycle of change. Enjoy

